This is one among a series of frequently asked interview questions in machine learning published in this website
Explain the terms Artificial Intelligence, Machine Learning, Deep Learning, and Reinforcement Learning?
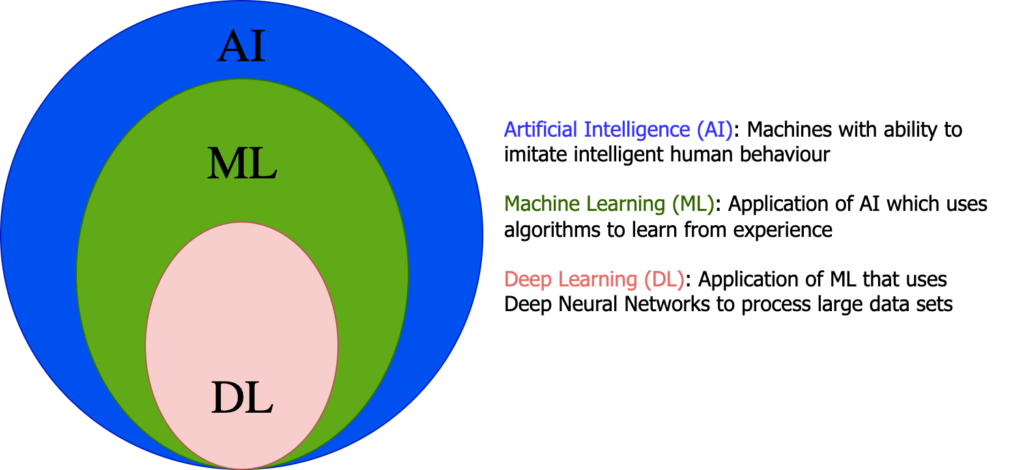
Artificial Intelligence (AI) is the domain of intelligent machines which can think rationally and act rationally. It uses algorithms to enable problem solving with robust dataset. Machine Learning (ML) and Deep Learning (DL) are subfields of artificial intelligence in which deep learning can be considered as a sub field of machine learning.
Machine learning algorithms can learn from experience in the training stage of data which is same as the case with deep learning. However, the learning methodology of deep learning and machine learning algorithms differ. Deep learning enables the use of larger data sets by executing self-actions in place of required human interventions. Deep learning uses Deep Neural Networks (DNN) comprised of more than three layers inclusive of the input and the output layers.
Reinforcement learning is a type of machine learning method in which ML programmed objects interact with the environment and learn to act accordingly by following trial and error methods. An example of reinforcement learning is the Robot vacuum named Roomba model 980 which uses reinforcement learning to detect the obstacles and thereby remember which route is best to perform its action of cleaning.
State the key difference between supervised and unsupervised machine learning?
| Supervised learning | Unsupervised learning |
| In supervised learning, the machine learning model is provided with both input data and output data | In unsupervised learning, the machine learning model is imparted with only the input data |
| Supervised learning requires supervision to train the model same as the case of a student needs a teacher to learn some topics | Unsupervised learning doesn’t require any kind of supervision to ensure the training process just like the case of a self-learning student |
| The data given to the supervised learning model has to be labeled | Unsupervised models can be trained by providing unlabeled data |
| In supervised learning, the model learns from the training data and predict the output on fresh data | The unsupervised learning extract the hidden patterns in the data and provide us useful insights from the complex data set |
| The task associated with supervised learning are classification and regression | Unsupervised learning comprised of associations and clustering problems |
Which method you will follow to select important variables when you are given with a data set?
The property called feature importance can give the importance of a feature in your data set. The feature importance provides you a quantitative score which is a measure of importance of a particular feature. The higher the score, the more relevant the feature is to find the output.
The following are some of the feature selection methods,
- Find the correlated variables based on correlation coefficient if the data is linear. We can select the features which has high correlation with target variable and low correlation among themselves.
- Information gain in the context of target variable can be used to understand which feature is important.
- When dealing with high dimensional data, we can use filter method without penalty for computation efficiency. Filter method uses intrinsic properties of features extracted using univariate analysis.
- If we are given with categorical features, we can employ Chi-square method. In this method, we can calculate the Chi-square score between each feature and target variable and select the features with best Chi-square scores.
- The forward feature selection which is an iterative method wherein we begin with a performing feature against the target feature and in the consecutive iteration we compare another best performing variable with the first selected variable and by repeating the iterations in this way we can find the best features. The backward feature elimination method is another commonly employed method to find best features which works in the reverse sense of forward feature selection method explained.
How can one decide which machine learning algorithm to use on a given data set?
The selection of an algorithm is problem specific and depends on the nature of the data and context. If the data is labeled, we have to use supervised learning algorithms and for unlabeled data, we have to apply unsupervised learning algorithms. If the optimization of the problem requires interaction with the environment, then it is a problem has to be treated with reinforcement learning algorithms. In addition, if the data is linear, linear regression can be a choice to try and bagging algorithms would be a try for nonlinear data. For business purposes, decision trees or support vector machines would be a choice.
As aforementioned, there is not an exact metric to decide which algorithm to use exactly for a particular data set. We have to perform exploratory data analysis (EDA) to understand the nature of the data and purpose of the problem and select an algorithm which best fit to the requirement of the problem and nature of the data.
What is Bias, Variance and explain Bias-Variance trade off?
Both bias and variance are errors in machine learning algorithms which has direct impact on the learning outcome of the model. Bias is a systematic error which often occurs when the assumptions are wrong in the training stage or the algorithm has less flexibility to deduce the correct information in the machine learning process. Bias happens when the model is inordinately simplified and it leads to underfitting on the data set.
Variance is a measure of how much the machine learning model can adjust with regard to the data set. Variance occurs when the model is sensitive to small fluctuations in the data set. If we add more features, it will result in complex models which in turn reduce bias and increase variance. Variance tells the changes in the model when we sample the data randomly and use different samples in the training stage.
| High Bias Model | High Variance Model |
| Originate from the inability to catch data trend | Caused by noise or outlier points in the data |
| Results in underfitting | Results in overfitting |
| Occur in inordinately simplified models | Occur in complex models with huge number of features |
There exists an inverse relation between bias and variance. For instance, linear regression is a high bias-low variance algorithm whereas random forest is a low bias-high variance algorithm and so on. In order to maintain an optimal performance level of a machine learning model, it is necessary to establish a delicate balance between bias and variance. The process of establishing this balance is called bias variance trade-off.
State the differences between covariance, correlation and causality in machine learning?
Covariance describes how the changes in one variable make changes in another variable. In a given stable condition, if one variable shows an increase or decrease with the increase or decrease in the base variable, then the two variables are said to have correlation. Positive covariance means the two variables either increase or decrease with the increase or decrease respectively in the other variable. If one variable shows a decrease with increase in the other variable or vice versa, the covariance is negative. The covariance value ranges from -$\alpha$ to +$\alpha$ in which negative value indicates negative covariance and positive value indicates positive covariance. The eigen value decomposition used to perform in the covariance matrix of principal component analysis method, which is a dimensionality reduction technique in machine learning, is an application of covariance in machine learning.
Correlation quantifies the degree to which two or more variables are related. If an equivalent change in one variable has the same impact in some way on the other variable. These two variables are said to be correlated.
Correlation is related to covariance as,
$correlation (x, y) = \frac{Cov(x, y)}{\sqrt(var(x)) \sqrt(var(y))}$
Causality occurs when one variable like x causes an outcome y. In correlation, the variable x is related to y whereas in causality x causes y.
Explain the role of regularization in machine learning?
Regularization is a technique used to reduce the errors in a machine learning model. It adjusts the loss function so as to prevent the underfitting or overfitting in the model.

A data set is given to you which has missing values spread along 2 standard deviations from the mean. Can you say how much percentage of the data is probably unaffected?
As it is mentioned that the data is spread across the mean, we can assume that it is a normal distribution. In normal distribution, about 68 % of the data is distributed at a distance of 1 standard deviation from the average tendency like mean, median or mode. Likewise, 95% of the data lies within a range of 2 standard deviations and 99.7 % of data lies in a region of 3 standard deviations from the mean. Here the missing values are spread along 2 standard deviations, hence 5% (i.e. (100-95) %) of data is unaffected.
How will you handle missing or corrupted values in a data set?
- Delete the rows or columns with majority (more than half) of the values as null values. But this procedure often led to loss of information if the missing values are huge in number as compared to the complete data set
- In the case of data set with continuous numeric values, we can impute mean or median in place of missing value
- In the case of data set with categorical features, we can impute most frequent category present in the entire column of data set in place of missing values
- We can handle missing values with the support of some machine learning algorithms such as K nearest neighbors (KNN), random forest, Naïve Bayes etc.
Explain the difference between stochastic gradient descent (SGD) and gradient descent (GD)?
Stochastic Gradient Descent (SGD) and Gradient Descent (GD) are algorithms that try to find parameters to minimize loss functions in an iterative manner. In GD we need to evaluate all the samples in the training data set to make an update for a parameter in the iterative process. This makes GD a compuationally demading process. While on the other hand, SGD performs evaluation on only one training sample to make an update on the set of parameters identified to reduce loss function/reduce error.
The next part of frequently asked interview questions in machine learning is available here.