This is one among the series of frequently asked interview questions in machine learning. Concepts are demonstrated with schematics wherever necessary
Differentiate between local optimization and global optimization
Optimization is a process of assigning a set of inputs to an objective function that can extract the best possible output from the objective function. Local optimization tries to find extrema points, i.e., maxima or minima of the objective function in some specific or predefined region of the input space.
Global optimization uses the entire input space to find the extrema (maxima or minima) for the objective function. If the objective function takes more than one global optima, then the optimization problem is called multimodal optimization.
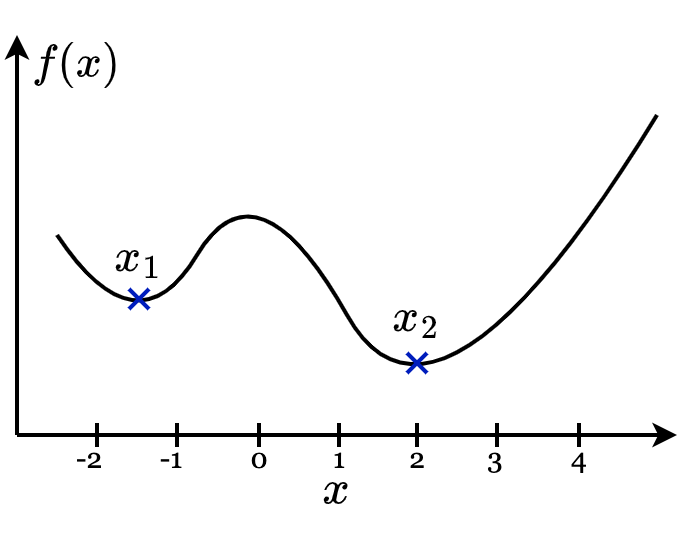
In the figure $x_1$ is the local extremum as $x_1$ uses only the negative region of input space to decide the minimum. On the other hand, $x_2$ uses the entire input space to find the minimum and hence it is a global extremum and the process is global optimization.
What is inductive bias in machine learning? Explain with some examples
Inductive bias refers to a set of assumptions followed by the learning algorithm in order to predict the output from the input which the algorithm has not encountered earlier. Inductive bias plays a crucial role in the capacity of a machine learning model to generalize its inferences from the training data (observations) on unseen data. A weak inductive bias causes the model to approach local optima whereas strong inductive bias leads the model to global optimum.
Examples
- Assumption that hyperplane separated negative class from positive class in support vector machines
- Assumption that output varies linearly with input when we apply linear regression
What is meant by instance-based learning?
Instance based learning is a procedure in machine learning in which the algorithm builds hypotheses from training instances. These training instances will be stored in memory. Each time the algorithm encounters a new query point, comparison of the new problem with these training instances will be performed instead of explicit generalization. Instance based learning is also called memory-based learning. Decision tree, K-nearest neighbor etc. are examples of instance-based learning.
The advantage of instance-based learning is its adaptability to new data. Also, we can use small approximations to assign target functions instead of using complete instance sets. The disadvantage with instance-based learning is each query point demands the creation of a new local model which in turn increases the computational complexity.
State Bayes’ theorem and explain its significance in data science
Bayes’ theorem describes how the probability of occurrence of an event is related to a condition. Bayes theorem deals with conditional probability of an event, means probability of an event depends on the previous events already occurred,
The formula for Bayes’ theorem is,
$$P(\frac{A}{B}) = \frac{P(\frac{B}{A}) \times P(A)}{P(B)}$$
Here,
$P(\frac{A}{B})$ is called posterior, means it measures how likely $A$ happens given that $B$ has happened
$P(\frac{B}{A})$ is called likelihood means how likely $B$ happens given that $A$ has happened already
$P(A)$ is called prior as it is a measure of how likely $A$ happens
$P(B)$ is called marginalization and it describes how likely $B$ happens
Bayes theorem is used in machine learning for classification purposes in terms of Naive Bayes classifier. Also, Bayes theorem serves in the development of Bayesian neural networks in deep learning.
What is Naive Bayes?
Naive Bayes is a classification algorithm in supervised machine learning. It makes predictions on the basis of probability using Bayes’ theorem. Spam filtration, article classification etc. are some of the applications of Naive Bayes classifier. The term “Naïve” indicates the occurrence of an event is independent of occurrence of another event, meaning each occurrence is Naïve. Bayes in Naïve Bayes conveys it is based on Bayes’ theorem.
Explain how hyperparameters are different from parameters in machine learning?. What is the significance of hyperparameters?
Parameters are variables in machine learning which is internal to the model. The model parameters will be calculated from the training data by the model by self-learning process. Coefficients of independent variables or weights in linear regression model and support vector machines are examples of parameters in the model.
The parameters which are explicitly defined by the user to control the learning process in a model are called hyperparameters. Hyperparameters are external to the model. Hyperparameters are essential to optimize the model and are independent of the data set. The value of hyperparameter can be extracted by the process of hyperparameter tuning. $K$ in $K$-nearest neighbors’ algorithm and learning rate in neural networks are examples of hyperparameters.
Differentiate between a linked list and an array
| Array | Linked list |
| Accessing specific elements is easy as the elements are well indexed | Accessing elements has to be done in cumulative manner and hence the process is slower |
| Array consist of elements of similar data type | Linked list is comprised of a combination of data and address |
| Array works with static memory | Linked list works with dynamic memory |
| Memory is allotted during the time of compilation | Memory allocated during run time |
| Array is slower to perform any operations like remove, insert, delete etc | Faster to perform operations like remove, insert, delete etc. |
Explain Eigenvalues and Eigenvectors
Eigen is a German word which means characteristic. So, eigenvectors and eigenvalues are established to express the characteristics of a matrix. In simple words eigenvectors are those vectors which are unaffected by a transformation. Eigenvalues quantify the amount by which the eigenvector is stretched.
Mathematically, the eigenvector $v$ and the eigenvalue $\lambda$ involved in a matrix transformation operation of matrix $\hat{A}$ is,
$$\hat{A} v = \lambda v$$
Explain the significance of p-value
In machine learning, the null hypothesis is an assumption which claims there is no relation between two types of features to be analyzed. P-value measures under the given condition that the null hypothesis is true, how likely it is to get a particular result. 0.05 is the reference level generally followed to understand p-value. If the p-value is less than 0.05, it is considered as a low value of p and it indicates our assumption that the null hypothesis is true is false. In such a circumstance we reject the null hypothesis and consider an alternate hypothesis.
How would you understand the optimum number of clusters in a clustering algorithm? Explain any one of the methods
The optimum number of clusters can be defined from the methods such as the Elbow method, Average Silhouette method, Gap statistic method etc.
The procedure to calculate optimum number of clusters using Elbow method in K-means cluster algorithm is as follows,
- Compute K-means clustering by varying the value of $k$, for instance $k$ = 1 to 10
- Calculate the value of Within clusters Sum of Squares (WSS) for each $k$
- Plot WSS with respect to the number of clusters in each $k$
- The region of bend in the plot is considered as the optimum number of clusters
The next part of interview questions in machine learning is available here.