Technical definition
Bias is a systematic error that happens during the machine learning model due to the incorrect assumptions taken during the training process of the machine learning model.
Narration
Imagine you pick up a group of cats and measure the height and weight of them. You are asked to find the height of another cat given its weight. What you can do in this situation? you can plot the data as a graph and visualize it.
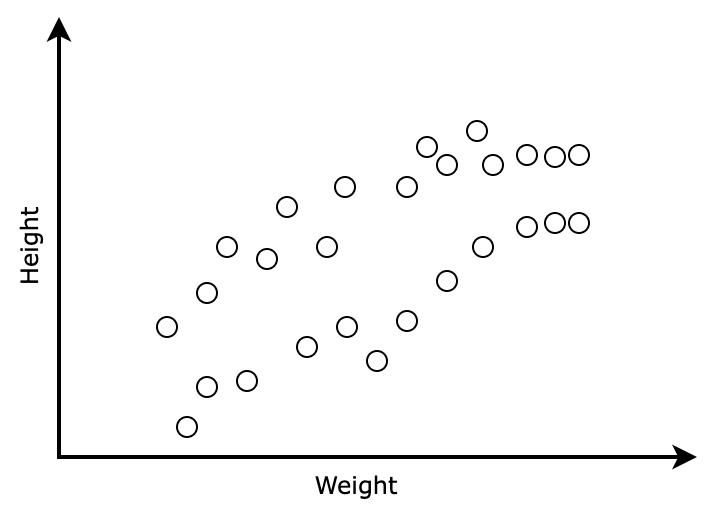
In the graph, you can see the lighter cats are shorter and heavier cats are tending to be taller but after a point, the height of the cats are not increasing with the weight.
Now you are given the weight of an unknown cat whose weight belongs to the range of the weight of cats you measured. The task is to find its height.
As we don’t know the mathematical relation between height and weight, we will seek the help of machine learning. As a first step, we can split the data into two sets called training data and test data.
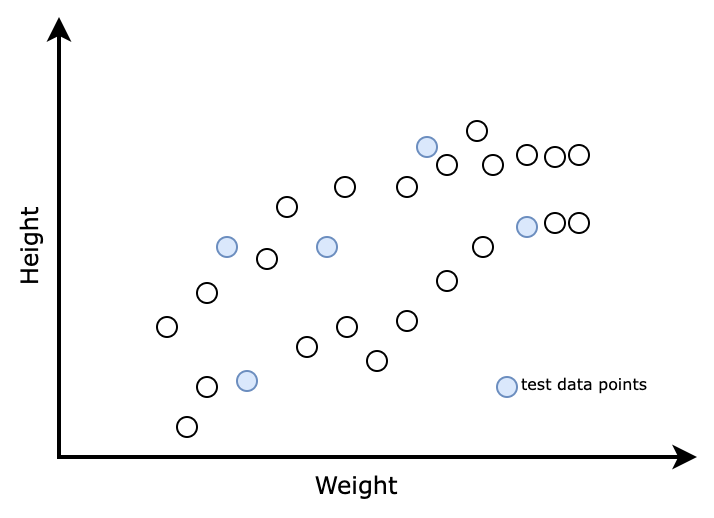
The data points shaded are points we select as test data and the non-shaded ones are selected as train data.
Consider we are using linear regression algorithms in machine learning to fit the training data. This algorithm uses a straight line as shown below to fit the data. The straight line lacks the flexibility to fit over all the lines in our training data set.
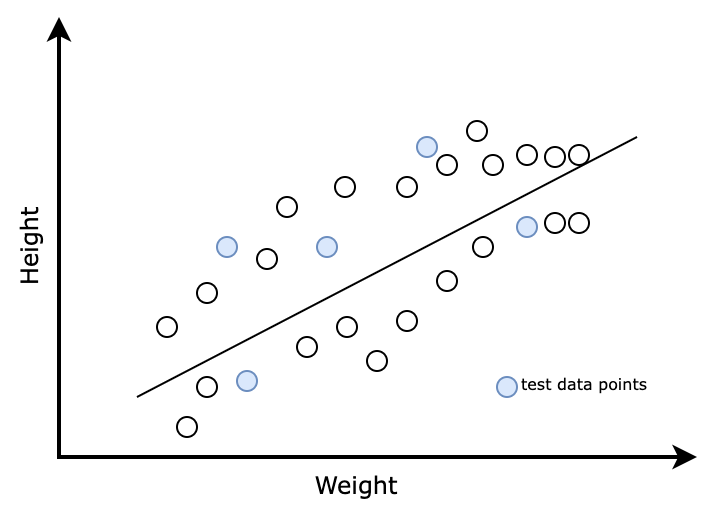
The actual data trend here is in the form of an arc. The straight line doesn’t have the capability to catch the actual trend of the data. So, it fails to understand the exact relationship between weight and height.
In general, what machine learning models do is, the model learns patterns from the training data, and then apply it to the test data to make predictions.
Here the model assumes a linear relationship. The model will apply this linear fit to the test data set to ensure the performance of the model. So, when you pass a new query point, here in this case the weight of an unknown cat, the result mayn’t be based on the actual trend of the data which is in the form of an arc. The result will be based on the linear trend which is a biased assumption taken by the algorithm during the training stage.
Understanding bias in detail
Bias is a phenomenon that manipulates the results of an algorithm based on the incorrect assumptions it took in the modeling process itself. The difference between the value predicted by the model and the actual value is called an error due to bias.
As the bias derives its route from the assumptions made during the process of modeling, every algorithm tends to get affected with some amount of bias such as either high bias or low bias.
A low bias model makes fewer assumptions about the nature of the target function/query point as compared to a high bias model.
Linear algorithms are observed to show high bias due to the simplicity in the assumptions it makes. Examples of high bias algorithms are linear regression, logistic regression etc.
On the other hand, nonlinear algorithms in general show low bias as it learns slowly by undergoing complex methods. Examples of low bias algorithms are support vector machines, Decision trees etc.
How to reduce high bias
High bias results in underfitting of the data. The essence of machine learning is to learn the correct pattern from the training data. We should be able to check the performance of the model using test data so that the model can be used to make predictions on fresh data.
So, reducing bias is crucial in the machine learning process. The following methods can be employed to reduce the bias up to some extent,
- Increase the size of the model: Increasing the size of the model will lead to more parameter optimization. So, the model gets an opportunity to learn many relationships among the parameters. This will result in an optimum model with reduced bias.
- Change the architecture of the model: This is more or less same as that of increasing the size of the model. But here we can take freedom to change how the model has to learn, what should be learned by the model, which activation function among sigmoid, tanh etc. has to use and we can change the hyperparameters as well to modify the model architecture. We have to redefine the architecture in a way to make the model learn the complex relationships. As mentioned, simplified learning results in high bias.
- Add more features: We can employ feature engineering to add more features to the training data. More features contribute more information to the learning process and it in effect results in a less biased model.
Tom Mitchel introduced the term bias in machine learning in 1980 with an intention to give importance to certain features so that we can generalize the inferences to larger data set. The term was first coined in the article titled “The need for biases in learning generalizations” by Tom Mitchel.
The concept bias in machine learning helps us make better generalizations by making our model less sensitive to some single point features. Though we give less weightage to certain features, the algorithm tends to be biased on certain features which we try to avoid its impact in the learning process. The algorithm does it by learning the latent representation of the feature we avoided from the features we considered. This is concerning in machine learning modeling and so steps has to be taken to reduce it.
The impact of bias in amplifying societal stereotype
Once Amazon attempted to build a resume filtering tool. The motive is to filter five best resumes out of a chunk of 100 resumes. The algorithm happens to get high bias with the feature gender and it started to reject women candidates though they possess equal qualification with a male. This can amplify the gender stereotypes that exist in society.
Machine learning has wider applications in medical diagnosis, fraud detection, security ensuring etc. In order to maintain such integral contributions, we have to manage the bias associated with machine learning algorithms with proper caution.