Defining neural network architecture is a key step in deep learning. A lot of decisions have to be made regarding the architecture, number of nodes, activations function, regularization etc. One of the the important aspect is combining multiple inputs parallely and passing it to the next layer. This is done using the Functional API of Keras. The other option is Sequential API. Here in this article, lets take a quick look at both cases and understand their pro and cons and usecase scenarios.
Sequential API
The sequential API is the simple option here. This is used when you do not want to combine multiple inputs but simply pass the output of one layer to the next. The sequential API is imported using the following code.
from keras.models import Sequential
After creating a model/sequential object, the only thing you have to take care of here is the input shape you are passing in. Suppose you are passing a feature row vector of 128 dimensions, the input shape will be that of (None, 128).
Once it is done, you can simply add as many layers on top of the input layer by simply using the “Add()” function.
The following code snippet shows the example of a simple three-layer architecture with two output nodes using sequential API.
from keras.layers import Dense
model = Sequential()
model.add(Dense(32,
activation="relu",
input_shape=(None, 128)))
model.add(Dense(2, activation="softmax"))
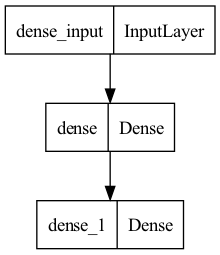
Once it is done, you can simply print the model summary or plot the model architecture to see how everything fits together.
from tensorflow.keras.utils import plot_model
plot_model(model,
to_file="Model.png")
Functional API
The simplicity of sequential API makes it impossible to pass multiple inputs or layer outputs concatenated to the next layer. This is where we find the functional API useful.
Following code snippet is an example on Functional API from Keras documentation.
from keras.layers import Input, Embedding
from keras.layers import LSTM, Dense, merge
from keras.models import Model
main_input = Input(shape=(100,),
dtype="int32",
name="main_input")
x = Embedding(output_dim=512,
input_dim=10000,
input_length=100)(main_input)
lstm_out = LSTM(32)(x)
auxiliary_loss = Dense(1,
activation="sigmoid",
name="aux_output")(lstm_out)
auxiliary_input = Input(shape=(5,),
name="aux_input")
x = merge([lstm_out,
auxiliary_input],
mode="concat")
x = Dense(64, activation="relu")(x)
x = Dense(64, activation="relu")(x)
x = Dense(64, activation="relu")(x)
main_loss = Dense(1,
activation="sigmoid",
name="main_output")(x)
model = Model(input=[main_input, auxiliary_input],
output=[main_loss, auxiliary_loss])
The model architecture will look like the following
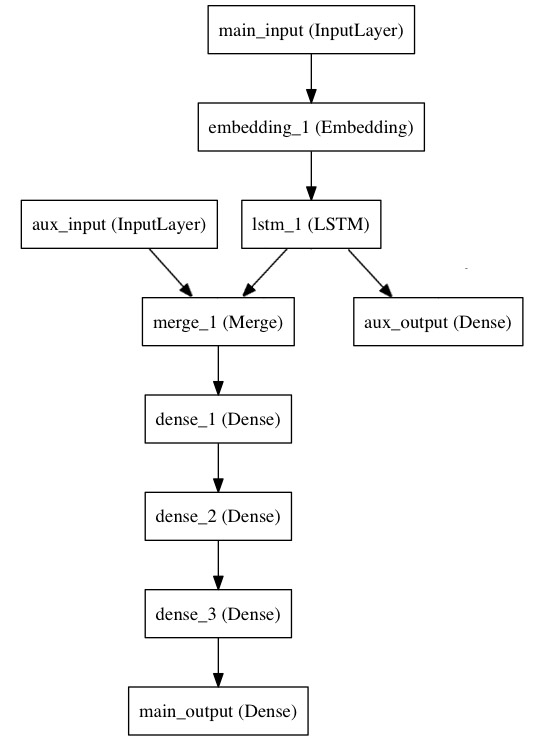
The first thing to notice here is that the model object is created only after defining the input layer, output layer, hidden layers, and connections between them. Whereas in sequential API, the model object is created first and different layers are simply added one on top of the next.
Here the outputs from the auxiliary output and LSTM output are merged and passed to the Dense 1 layer. Also, there are two outputs which are the main output and the auxiliary output.
As you can see both sequential and functional APIs has their own strength and weakness. Both are extremely be useful when they are applied at the right way for the right problem. For simple neural networks sequential API is the best. When complex network is required with muliple features and parallel connections, functional API is the way to go.