It is often required for aspiring data scientists to do portfolio projects either to show their skills or just simply for the pure joy of doing it. In either cases, the complexity of the project can be often a small one to medium one. To truly convince the recruiters, it is often required to do projects of substantial complexity. Free compute and storage for ML is a crucial resource for beginners to do these computationally demanding and storage heavy projects.
The complexity can be in terms of the compute resources required, RAM, and disk storage. Many hours of long data analysis and modeling pipelines require the aspirant to keep their laptops awake for a very long time. This is challenging because of the power constraints as well as might affect the battery health of the laptop.
Here in this article, I will explain how we can use computing and storage which are freely available to machine learning enthusiasts and how to best use it for computationally intensive projects where the data size can be greater than 100 GB.
The main two resources I have used in such cases are Kaggle notebooks & datasets and Google Colab. Both of these tools can be combined and compliment each other to overcome some special cases of challenges also.
Free Compute and Storage for ML
Kaggle Notebooks
A free Kaggle account can be registered at https://www.kaggle.com/. A good use case for a Kaggle notebook is when you want to run a time-consuming data preprocessing or data modeling pipeline without keeping your laptop awake all the time. This is possible by pressing the “save and run all” button before closing the notebook. Google Colab doesn’t have this feature but still we can use the best of both worlds to accomplish our requirements.
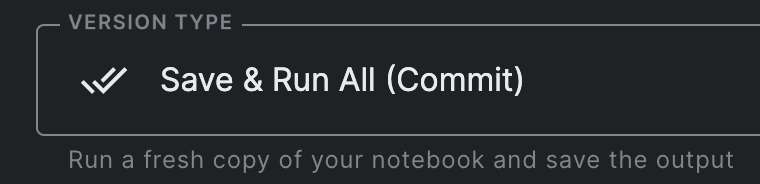
Version controlling and Notification Emails from Kaggle
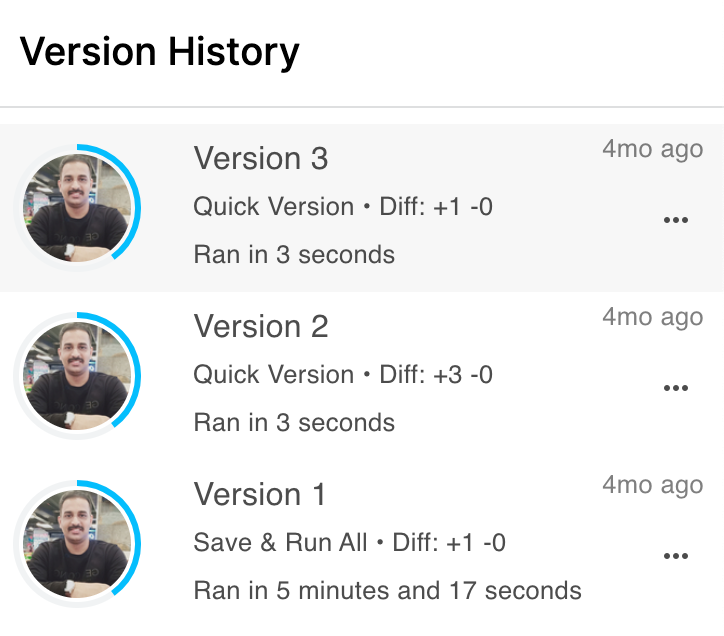
Kaggle automatically sends an email when the notebook is finished with success or failed message. Another nice feature is Kaggle automatical version controls your runs and you can always go back to previous versions of the notebook and run results. This can be accessed by clicking the version button on the right side once the notebook is finished for first time.
GPU and TPU Support
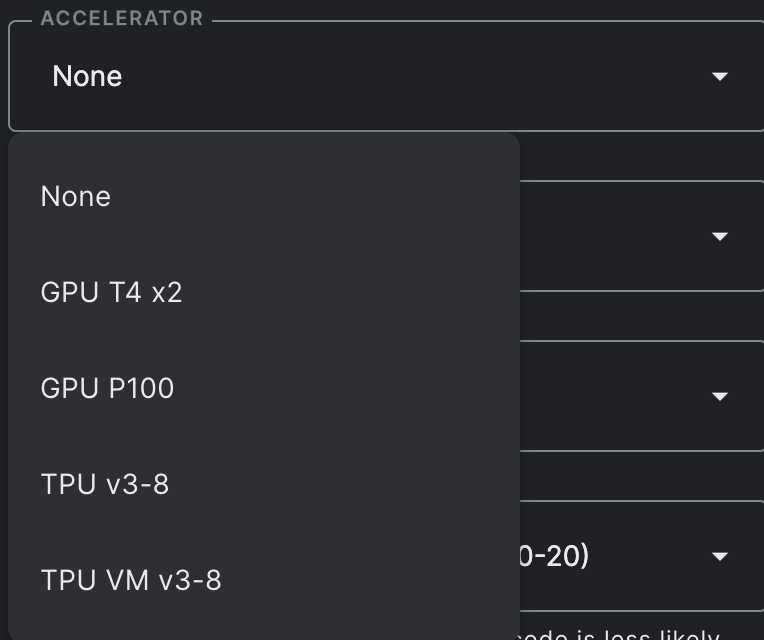
Kaggle also supports GPU (30 hours/week) and TPU(20 hours/week) access. In many cases, this much hours of GPU and TPU support is enough to do medium sized projects. It can be selected from the window shown on the right side of the notebook.
Internet Connectivity
This is especially useful if you want to download some files from the internet quite fast directly to the Kaggle workspace itself. We can use basic linux commands by prepending the exclamation symbol to accomplish this. For example, if you want to list out all files in a Kaggle directory or download a file from internet the following commands can be used.
!ls -lh #list files in the current location
!wget URL #download file from URL
Kaggle Datasets
Another great feature of Kaggle is the Kaggle datasets. We can create custom datasets in Kaggle by uploading files or we can use the output of notebooks previously run through the save and run all method discussed above. I would say this is the most useful feature of Kaggle for machine learning enthusiasts.
RAM Memory in Kaggle
The RAM availability is 30 GB. One drawback of the Kaggle notebook I feel is the available output disk space (20 GB). If the output disk space in use is exceeded the limit, the notebook can fail during execusion. This is where we can use Kaggle APIs in combination with Google Colab to overcome this issue.
Kaggle APIs
Kaggle allows us to download API as JSON files so that we can run notebooks, save versions of datasets, download data from Google drive etc. Since Kaggle’s output disk space is limitted to 20 GB, this feature can be used in combination with Colab.
Google Colab
Google Colab is a computing resource from Google and can be accessed freely at https://colab.research.google.com/. It requires a google account to operate.
Similar to the Kaggle notebook, colab also provides GPU and TPU support. It has more disk allocation (~100 GB) compared to the Kaggle notebook and a RAM space of 12 GB. But the downside is the non-availability of the save and run option. The colab notebook needs to be kept active until the notebook finishes.
When it comes to data preprocessing where large amounts of output file space is required it is possible to run it in Colab and upload it to Kaggle datasets using the Kaggle API. The following commands from Kaggle lets us create a Kaggle dataset, add files to it and save it as a new version.
!kaggle datasets init -p folder_dataset_name
!kaggle datasets version -p folder_dataset_name -m "Version message"
These preprocessed output files can be later used in Kaggle by adding them as datasets to the notebooks. All basic Linux commands can be used in colab (e.g. for file and folder management) just like I have shown with Kaggle notebook.
Installing Additional Python Packages
Many of the popular python packages are preinstalled in both Kaggle and Colab. However, if required, it is possible to download any additional package using the pip command as shown below.
!pip install package_name
Conclusion
By using the best of both Kaggle notebooks and Google Colab, it is possible to leverage some good computing and storage resources that are freely available to programmers. These platforms helped me immensily in some projects where I had to preprocess dataset of size ~100 GB without worrying about computing and storage capabalities of my laptop. By effectively combining Colab (for preprocessing as it is having more workspace) and Kaggle datasets (for saving preprocessed data), we can handle projects of moderate storage and compute requirements.