This article discusses a couple of machine learning (ML) interview questions asked frequently in data science related job roles.
When should we prefer ridge regression over lasso? Explain with reason
Ridge regression is a regression in which we use L2 regularization to give a penalty to the loss function to reduce loss in the optimization problem. As we are using L2 regularization, the square of the magnitude of the coefficients will be used for regularization. On the other hand, Lasso regression provides a penalty to loss function by using L1 regularization, i.e., it uses absolute value of magnitude of coefficients.
Ridge regression is preferred over Lasso regression in cases where the predictor variables are large in number as compared to the observed variables. If all target variables are important and we cannot nullify any one of them by making it sparse, then Lasso regression is not suitable. So, Ridge regression is a better choice when we deal with a higher number of target variables of considerable significance.
What will you understand if you get a high bias error in modeling and how will you handle it?
A high bias error indicates the algorithm fails to understand the relevant relationship between the given features and the target variable. The models with high bias error underfit due to the overly simplified assumptions it took during the training stage.
To reduce the high bias error,
- We need to increase the number of features so that the model get more input information to learn
- We can decrease the regularization term
- We need to increase the complexity of the model by adding features like polynomial features to avoid the simplified assumptions the model tend to make during training
Explain the role of maximum likelihood estimation in logistic regression
Maximum likelihood estimation is a method to find the line which best fit the data point while using logistic regression. In this method, a likelihood function is defined to find the probability of finding the target variable. The likelihood function is then optimized to get the largest value of sum likelihood from the training dataset.
Among Naïve Bayes and Decision tree algorithms, which one is better? Why?
It depends on the type of dataset we are handling and the nature of the problem we are trying to solve. whatsoever some general advantages of these algorithms are as follows,
Naïve Bayes:
- Faster, so can choose for real time predictions
- Requires small data for training as compared to that of decision tree
- Less sensitive to irrelevant features and hence less chance of overfitting
Decision Tree:
- Good interpretability and easy to do the debugging
- As it runs with if-else loop, large scale data preprocessing and feature transformations are not required
- Performs well even if some assumptions taken during training are not correct.
What can be the reasons for the choice of XGBoost compared to SVM in most of the business problems?
XGBoost is an ensemble model in which it uses outcomes of many models to ensure a satisfactory performance metric. Support vector machines (SVM) perform classification and regression using linear separators. To handle nonlinear data, SVM requires appropriate kernels. Finding suitable kernels for the dataset is a difficult task. Hence it is more convenient to use XGBoost over SVM.
Explain the basic steps to build a machine learning model
- Understand the problem and identify the constraints
- Data acquisition
- Data preprocessing: Data cleaning and Feature Engineering
- Exploratory data analysis
- Train the model
- Test/Evaluate the model
- Optimization of the model if required
- Model deployment
What is ensemble modeling? Explain its significance
Ensemble modeling is a method in which the output of miscellaneous models is used to create the final outcome. The miscellaneous models are created either by using different dataset for training or by using different algorithms. The diverse/miscellaneous models used to get the initial outcomes are called base models. In ensemble modeling, the output of each base model is aggregated based on the performance metric and then this ensembled model gives the final output.
The significance of ensemble approach is it reduces the generalization error. As we are using the output of multiple independent models, the error associated with prediction is less.
What is Random Forest? How does it work?
Random forest is a supervised machine learning algorithm which combines the output of multiple decision trees to get the final output. It is an ensemble model with a decision tree as base learners. Random forest is flexible to handle classification and regression problems.
The hyperparameters in random forest are the number of trees, size of the nodes and the number of features samples. We have to set the hyperparameters first and then proceed to further steps in modeling. In a random forest, each decision tree consists of a dataset sampled from the training set with replacement called the bootstrap sample. During each training iteration, one third of the sample will be preserved for testing which is called out of bag data. Randomness will be induced to the loop using feature bagging. Then the output from individual decision trees will be averaged for a regression task. Whereas, for classification tasks, the predicted class will be found out using a simple majority vote.
What is clustering?
Clustering is a method of grouping unlabeled data machine learning. The data points with similarities are grouped in the same cluster. The algorithm identifies patterns such as size, color, shape etc. and those with similar patterns are included in the same cluster. The clustering in which the data points can belong to any one of the clusters alone is called hard clustering. The clustering method in which there is flexibility to take data points to more than one cluster is called soft clustering.
Density based clustering, Hierarchical clustering, Fuzzy clustering etc. are some of the clustering techniques widely employed.
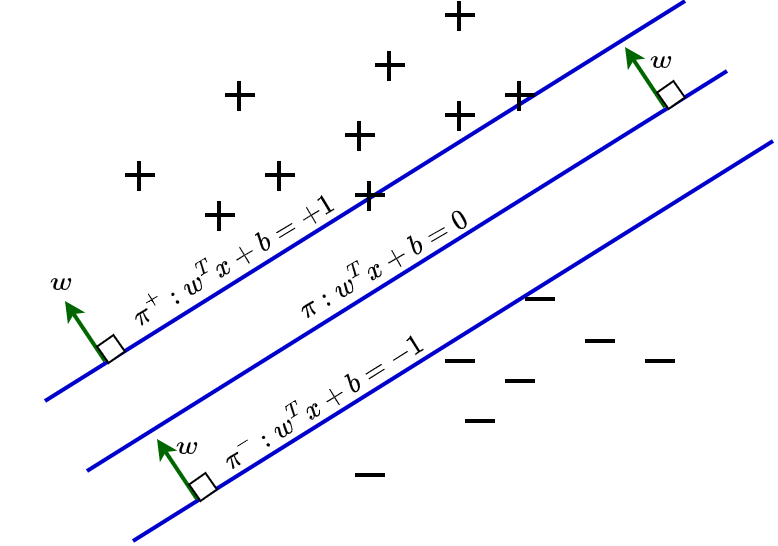
Explain the relevance of linear classifier in SVM
SVM is a type of linear classifier if we ignore advanced cases of kernels. SVM uses a hyperplane to separate the data by making use of their linear relationship. SVMs tries to maximize the margin between decision boundary. This way SVM is more robust to outliers and avoid misclassification of datapoints near to the decision boundary.
The previous article on ML interview questions can be found here