The K-nearest neighbor (KNN) is a supervised machine learning algorithm. KNN is used mostly to classify data points although it can perform regression as well. The K-Nearest Neighbors Algorithm classify new data points to a particular category based on its similarity with the other data points in that category.
The KNN algorithms grab the freedom to select any functional form from the training data to map the input data to the target data. KNN belongs to the category of nonparametric algorithms as this algorithm doesn’t take any specific assumption about the mapping function.
Real world use of KNN algorithm
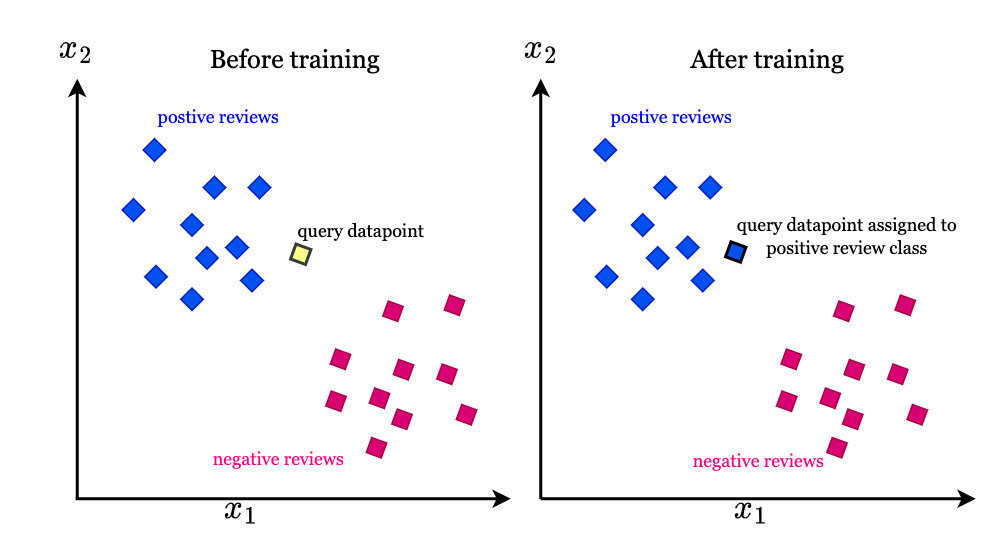
Suppose if we want to understand a new review belongs to the category of positive review or negative review. Each word in review will be converted into a vector for the sake of interpretability of a machine learning algorithm.
The KNN algorithm classifies the text vectors into the category of positive and negative review based on the similarity in the text vector it finds during training. The KNN algorithm learns a mathematical function to classify new data points to suitable categories based on its similarity to a particular group of text vectors.
Working principle of KNN
Given a query point, our task is to find the suitable category to which the query point can be assigned. KNN algorithms performs the following steps to execute this task of classification,
1. Decide the number $K$ in KNN
$K$ in KNN algorithms is the number of neighborhood points to a query point. The assignment of a class label to a query point depends on the hyperparameter $K$. i.e., if we assign a value of 5 for $K$, then we have to consider 5 nearest neighbor data points to the query point. The class label will be assigned based on the majority class label out of the 5 neighborhood points. $K$ can be assigned to any positive integer value but it is more likely to assign odd positive integers to avoid the tie arise while taking a majority vote to predict class label.
2. Find the similarity based on Euclidean distance
The shortest distance between two data points is called Euclidean distance,
In 2 dimension, the distance between $A(x_1, y_1)$ and $B(x_2, y_2)$ is,
$D= \sqrt{(x_2-x_1)^2-(y_2-y_1)^2}$
In this approach, the points which are closer are considered as more similar and grouped into the same category. The points which are farther away are treated as points belonging to different categories.
3. Measure the Euclidean distance of query point to K nearest neighbors
In the case we discussed with $K=5$, the KNN algorithm analyzes 5 data points which are at the shortest distance from the query point using Euclidean distance measure.
4. Assign the class label to the query point
The algorithm predicts the class label of the query point as the same as that of the majority data points in the neighborhood. It estimates out of the $K$ nearest neighbors, to which class the majority of the neighboring points belongs. It is presumed that the query point is more similar to the majority data points in the neighborhood based on Euclidean distance.
Other distance Measures in KNN
Though we discussed Euclidean distance as a distance measure for KNN algorithm in working principle. There are a couple of more distance measures which the KNN algorithm employs to find the distance and thereby the similarity between data points. The distance measures other than the widely used Euclidean distance are as follows,
- Manhattan distance
Manhattan distance is also called city block distance as it is more suitable to measure distance between points on a uniform grid such as a city block in Manhattan or like a chess board.
The Manhattan distance can be expressed as,
$D_M$=$ |X_1-X_2| + |Y_1-Y_2|$
As it is clear from the mathematical formulation, the Manhattan distance is the $L_1$ norm of vectors.
- Minkowski Distance
Minkowski distance is a generalized version of both Euclidean distance and Manhattan distance.
The mathematical formulation of Minkowski distance is,
$\sum_{i=1}^{n}((x_i-y_i)^p)^{\frac{1}{p}}$
- Cosine distance
Cosine similarity between two data points is the cosine of the angle between them.
i.e cosine similarity between $x_1$ and $x_2$ separated by an angle $\theta$ is $cos (\theta)$
The cosine similarity and cosine distance are related through the equation,
Cosine distance= 1-cosine similarity
KNN algorithms use cosine distance to find the similarity between nonlinear data points.
KNN algorithms for regression
The procedure for regression using KNN algorithm is almost the same as that of classification. The only difference is, in regression the algorithm takes the mean or median of nearest neighbors to assign the class label whereas for classification problems, the class label is assigned based on majority vote.
Step-by-Step Implementation of KNN algorithm using Python
Let’s understand implementation of KNN using Python step by step. We’ll use the scikit-learn library, a powerful tool for machine learning in Python.
Step 1: Importing Libraries
First, import the necessary libraries:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
Step 2: Loading Dataset
For this example, we’ll use the Iris dataset, a commonly used dataset for practicing classification algorithms.
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
Step 3: Preprocessing Data
Before applying KNN, it’s crucial to preprocess the data. We’ll split the dataset into training and testing sets and scale the features.
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Feature scaling
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
Step 4: Training the Model
Now, let’s instantiate the KNeighborsClassifier and train it on the training data.
# Instantiate KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
# Train the model
knn.fit(X_train, y_train)
Step 5: Making Predictions
With the trained model, we can make predictions on the test data.
# Make predictions
y_pred = knn.predict(X_test)
Step 6: Evaluating the Model
Finally, we’ll evaluate the performance of our model using accuracy as the metric.
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
Applications of KNN
KNN algorithm finds its application across various domains due to its simplicity and effectiveness in classification and regression tasks. Let’s explore some notable applications where KNN has proven to be valuable.
1. Image Recognition
In image recognition, KNN can be utilized to classify images into different categories based on their features. For instance, in facial recognition systems, KNN can help identify individuals by comparing their facial features with those in a database. Additionally, it’s employed in object detection and pattern recognition tasks.
2. Recommendation Systems
KNN serves as the backbone of collaborative filtering techniques in recommendation systems. By analyzing the preferences of similar users or items, KNN helps recommend products, movies, or music to users based on their past interactions or ratings. This application is widely seen in e-commerce platforms, streaming services, and social media platforms.
3. Medical Diagnosis
In the healthcare industry, KNN aids in medical diagnosis by classifying patients into different disease categories based on their symptoms, medical history, and test results. It helps healthcare professionals make informed decisions by predicting diseases or conditions and suggesting appropriate treatments.
4. Intrusion Detection
KNN is employed in cybersecurity for intrusion detection systems (IDS). By analyzing network traffic patterns, KNN can detect anomalies or suspicious activities that may indicate a security breach. It helps in identifying and preventing various types of cyber attacks, including malware infections, denial-of-service (DoS) attacks, and unauthorized access attempts.
5. Text Classification
Text classification tasks, such as sentiment analysis, spam detection, and language identification, benefit from the application of KNN. By analyzing the similarity between text documents based on their content or features, KNN can classify them into predefined categories. This application finds its use in social media analysis, customer feedback analysis, and content filtering.
6. Financial Forecasting
In finance, KNN is employed for predicting stock prices, credit risk assessment, and fraud detection. By analyzing historical financial data and market trends, KNN can identify patterns and make predictions about future market behavior or financial outcomes. It assists investors, financial analysts, and institutions in making informed investment decisions and managing risks.
Advantages of KNN
- The effectiveness of KNN increase with large training data and so it supports sufficient data representation
- KNN can be used for both classification and regression
- KNN is non parametric and hence no assumptions associated with the underlying data. Hence, it can be used for nonlinear data as well
- Implementation of KNN is simple
Disadvantages of KNN algorithm
- Measuring the distance between all data points in training samples is a computationally expensive task
- If the training data is excessively randomized, then assigning a class label based on distance measure is messy
- KNN is not a suitable option for query points at farther distance from the training data
Underfitting and overfitting in KNN
When the $K$ value is very small like $K=1$ or 2, the decision surface which separates different classes will not be smooth. The decision surface tries to make predictions with high accuracy in this case and it will lead to overfitting.
On the other hand, when the value of $K$ is too high like $K=n$, the decision surface itself vanishes and it results in a situation of classifying every query point as the majority class. This overly simplified assumption causes high bias and underfitting.
Bias-variance trade-off has to be done with hyperparameter tuning of $K$ values in order to get a smooth decision surface. Smooth decision surfaces can guarantee an optimal model which neither overfit nor underfit. Such a decision surface will be less prone to noise.
Space and time complexity of KNN algorithms
Space complexity of any algorithm is a measure of memory space required by an algorithm to process the input for a particular task. The space complexity of KNN algorithm is of the order of $n \times d$, denoted as $O(nd)$. Here, $n$ is the total number of data points used for training and d is the total number of features present.
Time complexity of any algorithm is a measure of how much time it takes to process the input data. Here, in the case of KNN algorithms, the time complexity is also $O(nd)$. However, we can reduce the time complexity of KNN algorithms to $O(log(n)) $ using the kd tree.
Interview Questions with answers from KNN
1. Can you explain the intuition behind the K Nearest Neighbors (KNN) algorithm?
Answer: Certainly. The KNN algorithm is based on the principle of similarity. It classifies a data point by considering the majority class among its K nearest neighbors. The algorithm calculates the distance between the data point and all other points in the dataset, then selects the K nearest neighbors based on this distance metric. Finally, it assigns the class label of the majority of these neighbors to the data point being classified.
2. How do you choose the value of K in the KNN algorithm?
Answer: The choice of K in KNN can significantly impact the model’s performance. A smaller value of K leads to a more flexible model, prone to noise and overfitting, while a larger K value results in a smoother decision boundary but may lead to bias. Selecting the optimal value of K involves balancing bias and variance. It is typically determined through techniques such as cross-validation, where different values of K are evaluated, and the one yielding the best performance metric (e.g., accuracy) on validation data is chosen.
3. What are the different distance metrics used in KNN?
Answer: The choice of distance metric in KNN depends on the nature of the data and the problem at hand. The most commonly used distance metrics include Euclidean distance, Manhattan distance, and Minkowski distance. Euclidean distance is suitable for continuous numerical data, while Manhattan distance is preferred for data with categorical or ordinal features. Minkowski distance is a generalization of both Euclidean and Manhattan distances and can be adjusted with a parameter (p) to suit different data types.
4. How does KNN handle categorical features in the dataset?
Answer: KNN can handle categorical features through appropriate encoding techniques. One common approach is to use one-hot encoding, where each category is represented as a binary feature. Another method is to convert categorical features into numerical values using label encoding. However, it’s essential to choose an encoding method that preserves the inherent characteristics of the categorical data and ensures meaningful distance calculations between data points.
5. What are the advantages and disadvantages of the KNN algorithm?
Answer: The advantages of the KNN algorithm include its simplicity, non-parametric nature (no assumptions about the underlying data distribution), and suitability for both classification and regression tasks. However, KNN has some limitations, such as computationally expensive predictions, sensitivity to irrelevant features, and the need for careful selection of the K parameter and distance metric. Additionally, it may not perform well with high-dimensional or imbalanced datasets.
Endnote
If you found KNN interesting, you’ll likely enjoy learning about Support Vector Machines (SVM), another powerful algorithm in the realm of supervised learning.
If you’re aspiring to pursue data science job roles, we’ve compiled a comprehensive folder of interview questions to support your preparation. Moreover, for those eager to explore deeper into machine learning, we encourage you to visit python foundation for machine learning and machine learning fundamentals in our website.
To further expand your understanding of machine learning algorithms and enhance your toolkit, I invite you to read our article on linear regression, logistic regression, ensemble models etc. available on this website. By connecting the concepts explored in the KNN article with those in the other articles on machine learning algorithms, you’ll gain a comprehensive understanding of different approaches to solving classification/regression problems.
If you are looking for more such tutorial style articles in machine learning, you can be find it here.
Happy learning, and may your journey into the realm of machine learning be both rewarding and enlightening!
Pingback: Large Language Models in Deep Learning - Intuitive Tutorials
Pingback: Exploring AI Models for Exoplanet Detection: A Comparative Study - Artificial Intelligence Article