Large language models (LLM) are general purpose language models in deep learning. The foremost word “Large” in LLM indicates a large training dataset which is often in the petabyte scale with an enormous number of parameters. General purpose means the models are capable of handling common problems in our day today life. The BERT model which is a chatbot developed by Google AI and the GPT-4 from OpenAI are examples of LLMs.
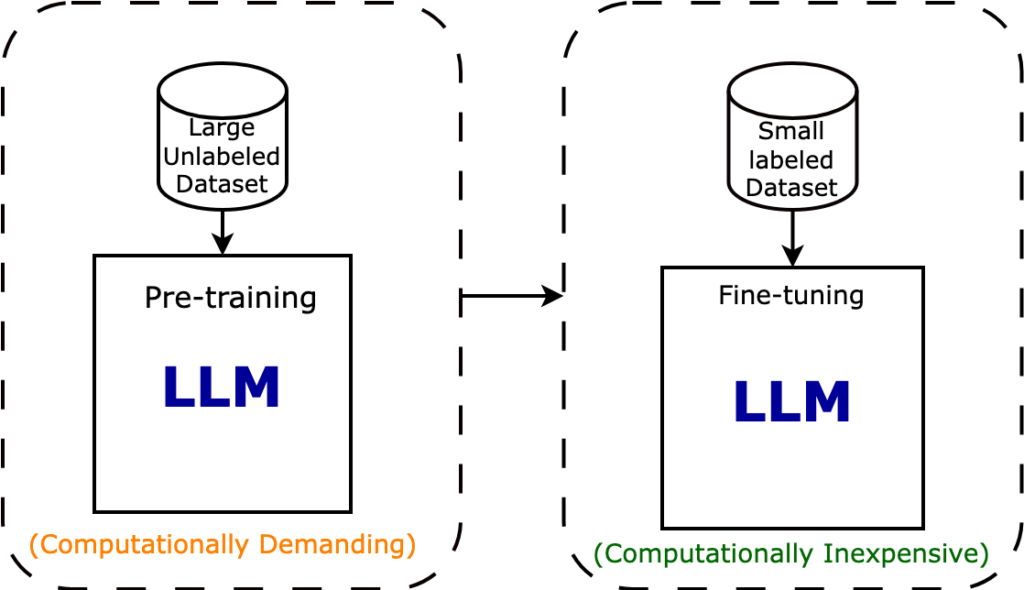
The LLM models are models which can be fine-tuned for specific purposes after the pre-training stage. The process of pre-training and fine-tuning can be understood like a person pre-trained to ride a bicycle can be fine-tuned to drive a motorbike.
Methodology of LLMs
LLM methodology follows the fine tuning of the models for specific purposes such as finance management, language translation, ecommerce, entertainment and so on and so forth. The models selected for such fine tuning are pre-trained for general purpose language concerns like text classification, document summarization etc. These pre-trained models are the fundamental language models. The commonality of human language irrespective of the task to be solved is the prime fact which helps to realize such models.
The LLM model undergoes deep learning when it passes through the process of transformer neural network. The self-attention mechanism in this process enables the LLM to learn the relationship and pattern among the words. The attention mechanism allows the model to perceive the texts as sentences or paragraphs instead of seeing one word at a time. This method provides better clarity about the context of words in the document as it captures long range dependencies among the words.
The LLM models used to be pre-trained for larger dataset and then fine tune with smaller dataset for specific purposes. Once the training process is complete, the fundamental model is generated upon which AI can be used to perform specific tasks.
Different Types of LLMs
The LLMSs are categorized into different categories such as generic (raw) language models, language representation model, Instruction tuned LLMs, Dialogue tuned LLMs and Multimodal model.
- Generic (raw) language models: These models are capable of predicting the next word based on the learning during the training.
- Language representation model: These models make use of transformers and deep learning suitable for natural language processing. BERT (Bidirectional Encoder Representation from Transformers) is an example of a language representation model.
- Instruction tuned language models: These models are trained to give a response to the input instructions.
- Dialogue tuned language models: Trained to deliver a dialogue by predicting the consecutive response.
- Multimodal Model: Multimodal models enlarge the scope of LLMs by accommodating image handling also in addition to the text based modeling tasks in conventional LLMs. GPT-4 is an example of a multimodal model.
Large Language Models in Industry
This section introduces some of the popular LLMs widely used in various industries
- Bidirectional Encoder Representation from Transformers (BERT): BERT was developed by google in 2018 and this model is based on the transformer neural network architecture. The natural language processing models till the time were mostly working based on the recurrent neural networks (RNN). RNN processes text data from left to right or right to left and combines them. The advantage with BERT is its bidirectional operation on text data which in turn allows one to comprehend the text contest with better clarity.
- Generative Pre-trained transformer-3 (GPT-3): GPT-3 developed by OpenAI is an LLM which gained attention owing to its capacity in natural language understanding and generation. GPT-3 shows appreciably high parameter analysis capacity compared to its predecessors.
- Generative Pre-trained transformer-4 (GPT-4): GPT-4 is yet another LLM developed by OpenAI and it is a multimodal LLM. GPT-4 is a breakthrough as it can process both text and image data as input and generate text as output. GPT-4 stands out in LLM models with its distinct steerability and advanced reasoning ability.
- Pathways Language Model-E (PaLM-E): PaLM-E is an embodied multimodal LLM developed by Google AI. This LLM works by incorporating observations into a pre-trained LLM. This model is established through token embedding. The input to this model can be text, images, robot states etc. and the output will always be text generated through auto regression. PaLM is trained using 540 billion parameters and is a transformer based model like BERT.
- BLOOM: Bloom is popular as the world’s largest open science, open access multilingual LLM. It is trained through the NVIDIA AI platform by using 176 billion parameters. Bloom has the capability for text generation in 46 languages.
Use Cases of Large Language Models
1. Text Generation
Large language models excel at generating coherent and contextually relevant text. They can be employed to generate creative writing, poetry, product descriptions, and more.
Example Code:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
text_prompt = "Once upon a time, in a land far away"
input_ids = tokenizer.encode(text_prompt, return_tensors="pt")
output = model.generate(input_ids, max_length=100, num_return_sequences=1, temperature=0.7)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
Explanation: Utilizing the GPT-2 model, this code snippet generates text based on a given prompt. The tokenizer tokenizes the input text, and the model generates the output text. Adjusting the temperature parameter controls the randomness of the generated text.
2. Sentiment Analysis
Large language models can analyze the sentiment of text, determining whether it is positive, negative, or neutral. This capability is useful for social media monitoring, customer feedback analysis, and brand reputation management.
Example Code:
from transformers import pipeline
sentiment_analysis = pipeline("sentiment-analysis")
text = "I love this product, it's amazing!"
result = sentiment_analysis(text)
print(result)
Explanation: The sentiment analysis pipeline provided by the Hugging Face Transformers library facilitates easy access to pre-trained models for various tasks. In this example, the sentiment analysis pipeline is utilized to analyze the sentiment of the given text.
3. Text Summarization
LLMs can summarize long passages of text into concise summaries, preserving the key information. This functionality is beneficial for skimming through large documents, news articles, or academic papers.
Example Code:
from transformers import pipeline
summarization = pipeline("summarization")
text = """
In a groundbreaking discovery, scientists have found evidence of water on Mars.
The discovery was made using a special instrument on the Mars rover, which detected
signs of H2O beneath the planet's surface. This finding has significant implications
for the possibility of life on Mars and future human exploration missions.
"""
summary = summarization(text)
print(summary[0]['summary_text'])
Explanation: Using the summarization pipeline, the model condenses the input text into a shorter summary, encapsulating the main points of the original text.
4. Language Translation
LLMs can translate text from one language to another, facilitating communication across different linguistic boundaries.
Example Code:
from transformers import pipeline
translator = pipeline("translation_en_to_fr")
text = "Hello, how are you?"
translated_text = translator(text)
print(translated_text[0]['translation_text'])
Explanation: This code snippet demonstrates the use of a pre-trained model to translate English text into French. The pipeline function simplifies the process of using pre-trained models for various tasks.
Advantages of Large Language Models
- LLMs can be used for different purposes with minimal field training
- Fine tuning to specific task requires only a small amount of data
- LLMs show good performance even for the tasks which are not explicitly taught during the training
- Performance of LLMs improves with each addition of parameters and with the increase of size of the dataset
- LLM development with pre-trained application programming interfaces (APIs) doesn’t require machine learning expertise, training examples or domain knowledge
- LLMs are able to provide rapid low latency responses
- LLMs can be trained with unlabeled data and so the training process is comparatively easy
Limitations of LLMs
- LLM requires huge amount of data for training and massive quantity of graphics processing unit, which make the development cost high
- Bias associated with unlabeled data may affect the performance of the model
- It is difficult to explain how an LLM model perform a specific task and produce the suitable outcome
- The prompts which are maliciously designed may make an LLM model malfunction. This is called glitch tokens. LLMs suffer from glitch tokens.
- LLMs demands high operational costs
Conclusion
LLM are transformer models built on a large scale. These models can understand language and produce the suitable response as texts. These models have the potential to generate responses for an enlarged domain as they are trained with diverse sources of text data such as journals, websites, and books. LLMs are expected to transform various industries with its applications like question-answering, sentiment analysis, text summarization, language translation, code-generation and more intriguing possibilities much awaited!
If you’re motivated by the fascinating world of machine learning and eager to explore further, I highly encourage you to go through K Nearest Neighbors (KNN), Support Vector Machines (SVM), and ensemble models published in this website and do suggest it to your friends and colleagues
If you’re aspiring to pursue data science job roles, we’ve compiled a comprehensive folder of interview questions to support your preparation. Moreover, for those eager to explore deeper into machine learning, we encourage you to visit python foundation for machine learning and machine learning fundamentals in our website. Let’s continue our learning journey together, fuelled by curiosity and a passion for innovation in data science and machine learning!
For constant learning do subscribe to this blog by entering your name and email id in the subscription option in the page