Simplex explained in one minute
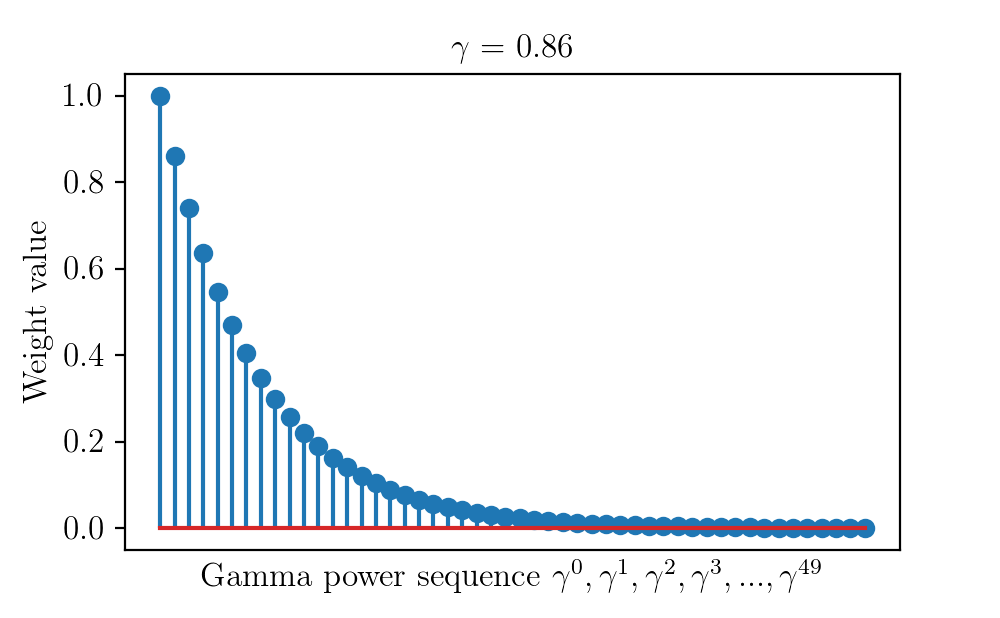
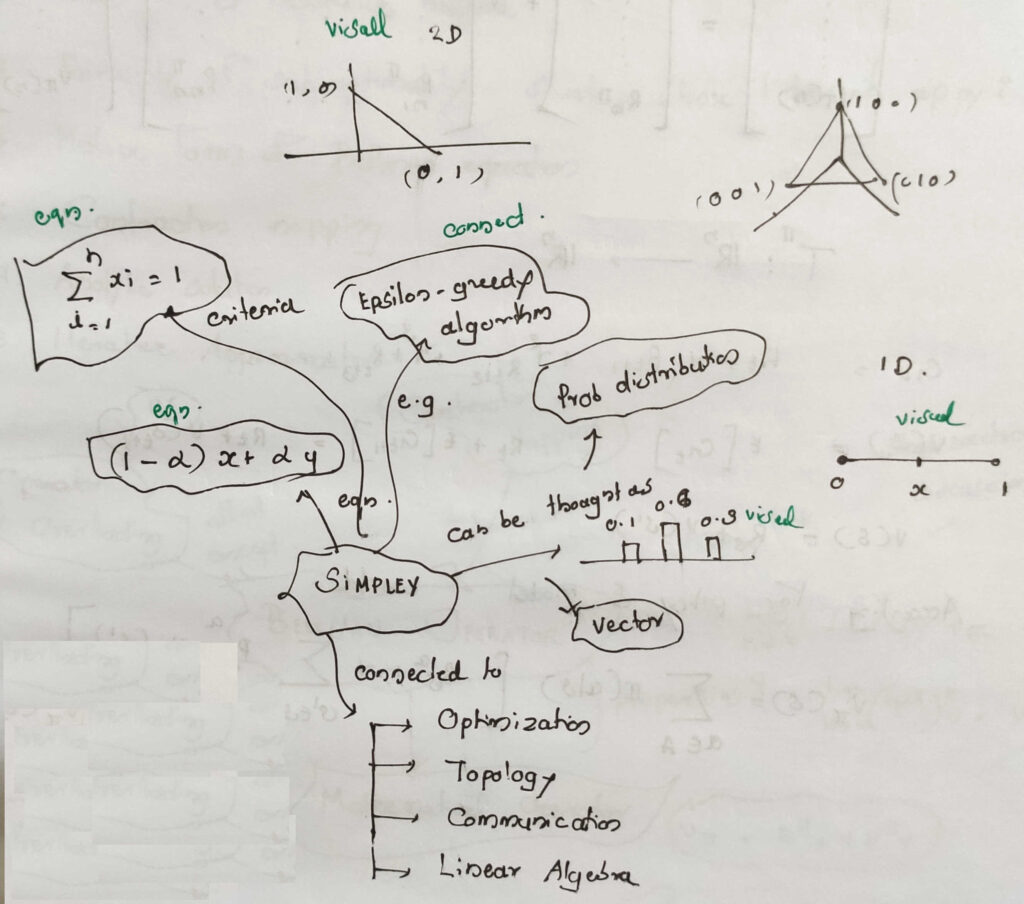
The concept of simplex appears in science and engineering over and over again. For example it appears in optimization, information theory, communication systems, linear algebra, etc. Let’s have a quick look at it from different contexts. In general, simplex can be thought of as a mathematical expression of $\alpha x + (1-\alpha)y$. It can be […]
Simplex explained in one minute Read More »